Kubernetes Cluster Autoscaler with Magnum CAPI Driver
- 4 minsIn previous blog, I have deployed Kubernetes cluster using Openstack Magnum Cluster API. In this blog I am going to test autoscaling feature with kubernetes clustuse using magnum capi driver.
Autoscaling is very nessessary due to higher loads peak hours, but we noticed most worker nodes were left idle during lower load periods like nights and weekends, thus wasting our budget and resources. Thanks to autoscaler now we managed to reduce resources usage and same time maintaining a performance and responsive application.
Scope
- Create k8s cluster
- Deploy sample ngnix application
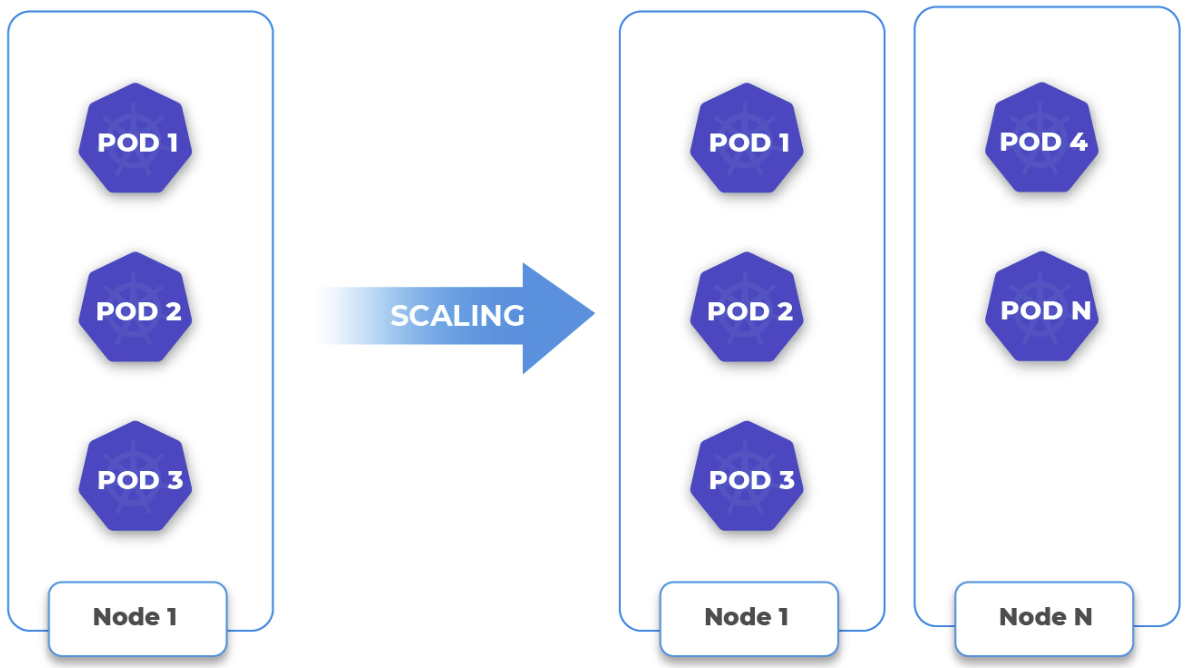
- Create more replica copy to increase load on worker nodes
- Observe scaling up/down of worker nodes
Create k8s cluster
$ openstack coe cluster create mycluster --cluster-template k8s-v1.27.4 --node-count 1 --master-count 1 --labels auto_scaling_enabled=true,min_node_count=1,max_node_count=3
Verify status of autoscaling label
$ openstack coe cluster show mycluster -c labels_added
+--------------+--------------------------------------------------------------------------------+
| Field | Value |
+--------------+--------------------------------------------------------------------------------+
| labels_added | {'auto_scaling_enabled': 'true', 'min_node_count': '1', 'max_node_count': '3'} |
+--------------+--------------------------------------------------------------------------------+
openstack coe cluster list
+--------------------------------------+--------------------+-------------------+------------+--------------+--------------------+---------------+
| uuid | name | keypair | node_count | master_count | status | health_status |
+--------------------------------------+--------------------+-------------------+------------+--------------+--------------------+---------------+
| b77d7cb5-b0bd-4279-b5b7-c8fcbb39a568 | mycluster | None | 1 | 1 | CREATE_COMPLETE | HEALTHY |
+--------------------------------------+--------------------+-------------------+------------+--------------+--------------------+---------------+
Deploy sample ngnix application
First ontain kubeconfig file to access cluster
$ openstack coe cluster config mycluster
export KUBECONFIG=/root/k8s/config
$ export KUBECONFIG=/root/k8s/config
Check nodes using kubectl. We have 1 master & 1 worker node.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-893ps-default-worker-n5ggx-hv4nn Ready worker 3m57s v1.27.4
kube-893ps-m7x4x-5spmc Ready control-plane,master 5m20s v1.27.4
Deploy application.
$ kubectl create -f https://k8s.io/examples/application/deployment.yaml
deployment.apps/nginx-deployment created$ kubectl get deploy
Check deployment.
kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/2 2 2 46s
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-cbdccf466-fwbzl 1/1 Running 0 70s
nginx-deployment-cbdccf466-zs7mm 1/1 Running 0 70s
Scaling-Up
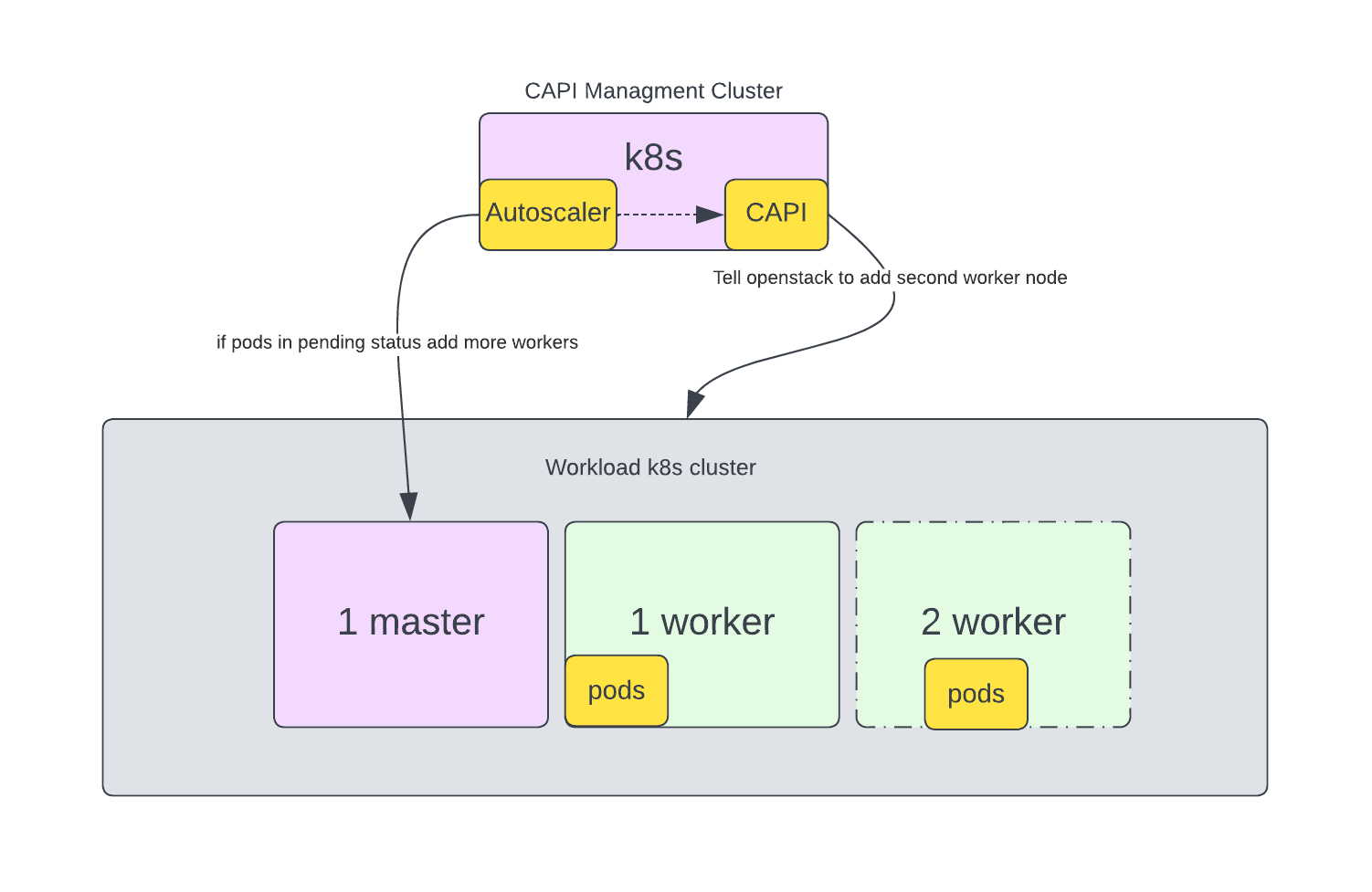
Create more replicaset for ngnix deployment to put some load on single worker node to scaling up cluster.
$ kubectl scale deployment --replicas=120 nginx-deployment
Check status of pods and see if they are in pending state.
$ kubectl get pods | grep -i pending
nginx-deployment-cbdccf466-298dh 0/1 Pending 0 3s
nginx-deployment-cbdccf466-2jpbk 0/1 Pending 0 3s
nginx-deployment-cbdccf466-9d5gz 0/1 Pending 0 3s
nginx-deployment-cbdccf466-b5mxb 0/1 Pending 0 3s
nginx-deployment-cbdccf466-gt949 0/1 Pending 0 3s
nginx-deployment-cbdccf466-j6fh6 0/1 Pending 0 3s
nginx-deployment-cbdccf466-kxmb9 0/1 Pending 0 3s
Wait for few minutes and you will see new worker node has been added to cluster. Voilla!!
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-893ps-default-worker-n5ggx-77mft Ready worker 2m2s v1.27.4
kube-893ps-default-worker-n5ggx-hv4nn Ready worker 3h16m v1.27.4
kube-893ps-m7x4x-5spmc Ready control-plane,master 3h17m v1.27.4
Verify distribution of pods across worker nodes.
kubectl get pods -o jsonpath='{range .items[?(@.spec.nodeName)]}{.spec.nodeName}{"\n"}{end}' | sort | uniq -c | sort -rn
106 kube-893ps-default-worker-n5ggx-hv4nn
14 kube-893ps-default-worker-n5ggx-77mft
Scaling-Down
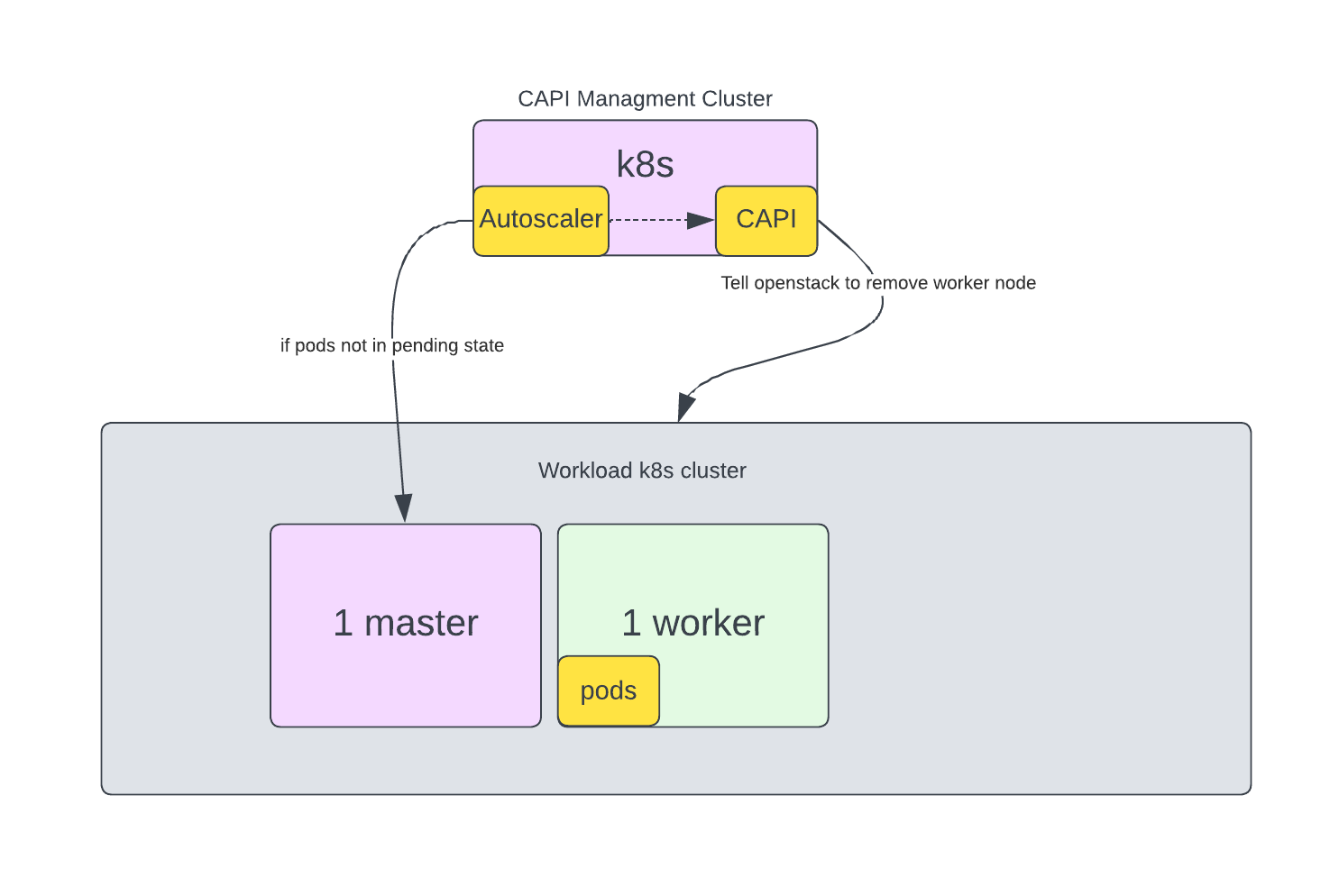
Let’s reduce replicaset of deployment to trigger scale down of cluster.
$ kubectl scale deployment --replicas=20 nginx-deployment
deployment.apps/nginx-deployment scaled
Verify distribution
$ kubectl get pods -o jsonpath='{range .items[?(@.spec.nodeName)]}{.spec.nodeName}{"\n"}{end}' | sort | uniq -c | sort -rn
14 kube-893ps-default-worker-n5ggx-77mft
6 kube-893ps-default-worker-n5ggx-hv4nn
Wait for few minutes because default time of scale down is 10min.
$ kubectl get pods -o jsonpath='{range .items[?(@.spec.nodeName)]}{.spec.nodeName}{"\n"}{end}' | sort | uniq -c | sort -rn
20 kube-893ps-default-worker-n5ggx-hv4nn
Finally, autoscaler removed worker node.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube-893ps-default-worker-n5ggx-hv4nn Ready worker 3h37m v1.27.4
kube-893ps-m7x4x-5spmc Ready control-plane,master 3h38m v1.27.4
Check logs of CAPI driver
Go to clusterapi managment cluster to check status of cluster and logs of autoscaler.
$ kubectl get cluster -n magnum-system
NAME CLUSTERCLASS PHASE AGE VERSION
kube-893ps magnum-v0.13.3 Provisioned 3h43m v1.27.4
Find autoscaler deployment and pod for your workload cluster running inside openstack.
$ kubectl get pods -A | grep kube-893ps
magnum-system kube-893ps-autoscaler-77db46897b-kp7t6 1/1 Running 2 (3h42m ago) 3h44m
Check logs of autoscaler pod for your cluster.
$ kubectl logs kube-893ps-autoscaler-77db46897b-kp7t6 -n magnum-system -f
...
...
I0111 20:23:12.535242 1 static_autoscaler.go:632] Starting scale down
I0111 20:23:12.728882 1 request.go:628] Waited for 193.458486ms due to client-side throttling, not priority and fairness, request: GET:https://10.233.0.1:443/apis/cluster.x-k8s.io/v1beta1/namespaces/magnum-system/machinedeployments/kube-893ps-default-worker-np2v5/scale
I0111 20:23:12.733352 1 clusterapi_provider.go:68] discovered node group: MachineDeployment/magnum-system/kube-893ps-default-worker-np2v5 (min: 1, max: 3, replicas: 1)
I0111 20:23:12.733398 1 legacy.go:296] No candidates for scale down
Enjoy!!!